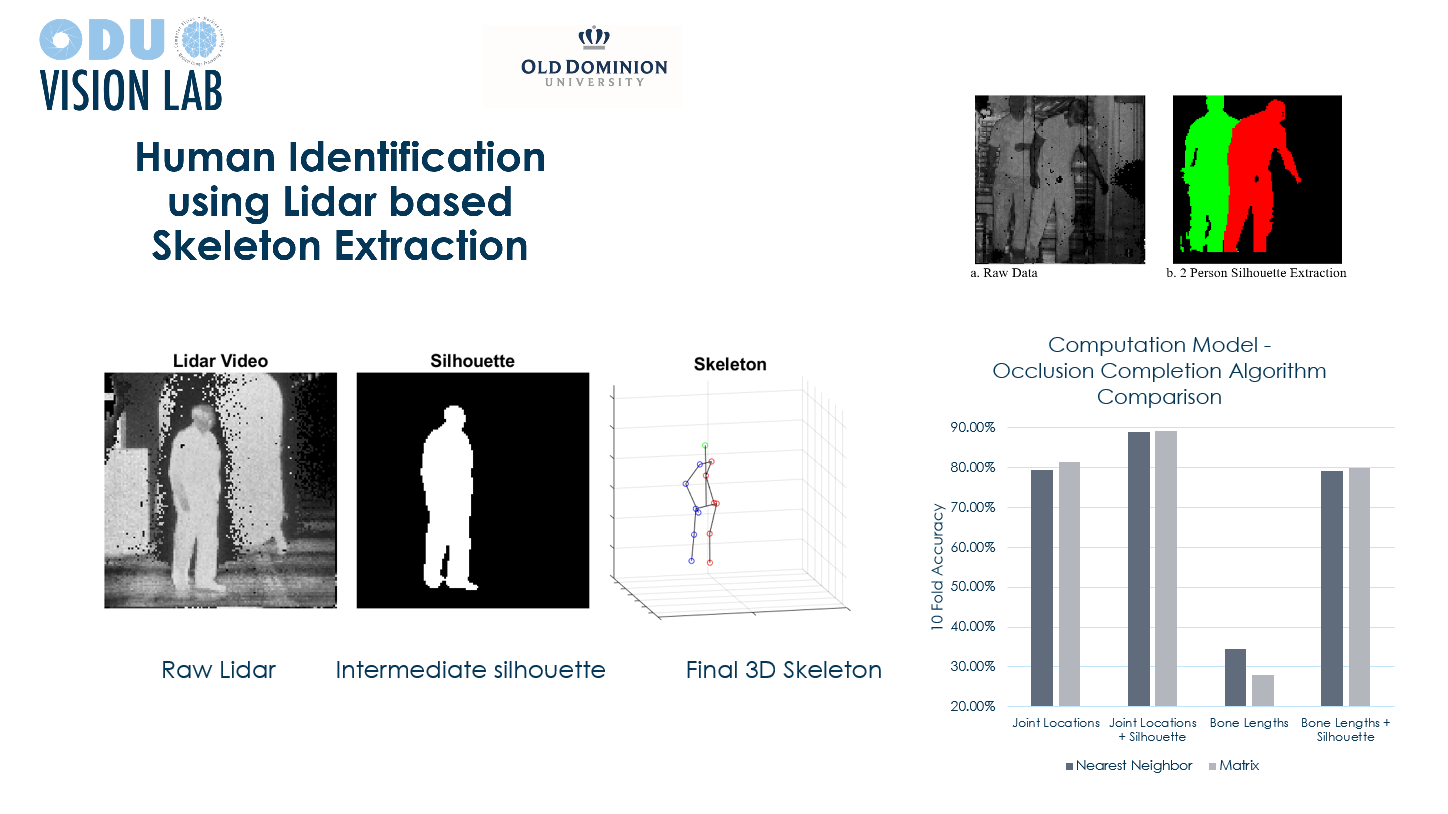
This work proposes a novel computational modeling to estimate 3D dense skeleton and corresponding joint locations from Lidar (light detection and ranging) full motion video (FMV). Unlike motion capture (MoCap) video, where body mounted reflectors are used to capture 3D skeleton in a controlled research environment, the proposed model obtains full 3D dense skeleton in Lidar FMV. Our proposed method extracts 3D pose for subjects with walking motion from the 3D dense joints. The second contribution involves extraction of silhouette based features and augmentation of the pose features with silhouette-based features generated over small windows of the video for human subject identification. We evaluate our model with a 10-person in-house Lidar FMV dataset and the proposed method offers 91.69% of cross-validated accuracy using a support vector machine (SVM) classification. For comparison, we implement transfer learning for another well-known deep learning-based human identification method, OpenPose, using the same Lidar FMV. The fully tuned OpenPose offers 85.00% cross-validated identification rate using the same dataset. The comparison suggests that the proposed computational modeling offers better human identification performance when compared to OpenPose transfer learning method using the 10-person Lidar FMV.
click image to enlarge
click image to enlarge